<이 내용은 강원대학교 전자공학과 실시간 신호처리 과목에서 진행된 내용을 기반으로 작성되었습니다.>
이전 LAB5에서 우리는 핑퐁버퍼를 사용하였다. 이는 매우 효율적인 시스템을 자랑하였지만 아직 아쉬운 점이 남아있었다. 전에도 이야기 하였지만 바로 매번 인터럽트를 받아온다는 사실이 바로 그것이다. 그리고 이 문제를 DMA를 통해 해결할 것이다.
DMA는 Direct Memory Access의 약자로 메모리의 데이터 이동을 담당하는 하나의 도구이다. 우리 보드에 있는 DMA를 ti에서는 조금 더 발전된, 향상된 DMA라는 의미로 Enhanced를 앞에 붙여 EDMA라고 부른다. (정말로 Enhanced 되어있다.)
CPU가 요리사라고 해보자. 매우 잘나가고 몸값이 비싼 요리사이다. 그런데 매일같이 하는 일의 대부분이 요리 재료를 사오고 손질하고 꺼내오고 창고를 정리하는 일이라면 그 솜씨 좋은 요리사를 제대로 활용하지 못하는 것일 것이다. 이럴 때 사용하는 것이 바로 요리사 보조이다. 요리사 보조를 고용하여 단순한 일들을 맡긴다면 요리사는 더욱 더 많은 요리를 효율적으로 할 수 있을 것이다. 이런 요리사 보조가 바로 DMA라고 할 수 있다. CPU는 연산과정을 담당하고 DMA는 데이터를 가져오고 가져가는 일을 담당하는 것이다.
DMA에 대해 자세히 알아보자. DMA에게 일을 시키기 위해서는 결국 CPU가 명령을 내려야 한다. 그런데 만약 데이터 하나를 가져오라고 DMA에게 CPU가 명령을 한다면? 직접 가져오는 것과 다를 바가 없을 것이다. (둘 다 1사이클의 명령어가 필요하므로) 그렇기 때문에 CPU는 DMA에게 일괄적으로 명령을 내린다. 리스트를 작성하여 전달하면 요리하는 동안 재료를 하나씩 순차적으로 계속하여 가져오는 것이다. 그렇기에 CPU는 DMA에게 어디에 있는 데이터를 어디로 옮기라는 명령을 해야 할 것이다. 이를 Source와 Destination으로 표현한다. 어디에 있는 데이터인지 알려주는 것이 source address이며 어디로 옮기라는 것이 destination이다. 아주 단순한 DMA는 이 기능만 가지고 있는 경우도 있다. 그저 시작 위치와 사이즈만 알려주면 그게 만개든 십 만개든 데이터를 주구장창 옮겨줄 수 있는 것이다. 하지만 이렇게 단순하면 EDMA라고 할 리가 없다. Ti가 말한 EDMA의 기능들은 무엇일까? 알아보도록 하자.

기능을 알아보기에 앞서 우선
우리가 사용하는 DMA의 구조를 알아야 한다. 작동 순서와 원리 또한 자세히 알아야 한다. 그래야 사용할 수 있고, 원하는 기능을 DMA를 통해 구현할 수 있을 것이다. 위 사진에서 그냥 DMA라 적혀진 네모 박스가 바로 ti에서 말하는 EDMA이다. 그림을 자세히 보면 64채널을 가지고 있다. 그 밑에 QDMA는 특화된 기능만 가지고 있으나 아주 빠르게 동작할 수 있는 DMA이고 4개의 채널을 가지고 있다.
채널이 뭘까? 비유하자면 채널은 하인의 개수이다. 64채널이 있으면 하인이 64명이 있는 것이다. CPU입장에선 64개의 명령을 내릴 수 있는 것이다. 만약 64개의 명령을 내렸다면 64개의 데이터가 동시에 움직일 것이다. 이 때, 64명이 동시에 움직이지만 길은 하나라는 문제가 있다. 동시에 움직이되 길은 하나이기 때문에 어느 한 순간에는 한 명만 움직이다. 이 길은 데이터를 엑세스 하는 길이라고 생각하면 된다. 데이터에 접근하는 것은 DMA뿐 아니라 CPU또한 자주 하는 작업일 것이다. 그러나 CPU가 데이터를 access하는 순간은 그리 많지 않기 때문에 그 길을 DMA가 CPU가 안 쓰는 순간에 계속 사용할 수 있다. 이 때 DMA의 순서는 round로 돌기도 하고 우선순위를 할당해 사용자가 조정할 수도 있다. 심지어는 CPU가 우선인지 DMA가 우선인지도 정할 수 있다.
DMA가 데이터를 옮기는 방식을 Synchronized move와 NoSync로 나눌 수 있다. 싱크가 무엇일까? 메모리를 Dump하는 케이스를 생각해보자. CPU가 명령을 내리면 DMA는 해당 명령에 맞추어 데이터를 복사하여 옮길 것이다. 이 때 이 동작은 어떠한 이벤트와도 무관하게 작동된다. 즉, 창고가 두 개 있을 때 한쪽의 물건을 다른 한쪽으로 옮기라는 명령과 같이 이벤트와 무관한 동작을 바로 NoSync라고 한다. 이에 반해 싱크로나이즈드 무브는 이벤트가 존재한다. 일상생활 속 예를 들어보면 물건이 배달이 오면 초인종이 울리는데 그 때 그거 가지고 오라는 명령을 내린다고 해보자. 이 명령에는 초인종이라는 이벤트가 존재한다. 어떠한 이벤트에 상응하는 동작을 요구하는 동작이 바로 Synchronized move인 것이다.
기존에 사용한 핑퐁버퍼를 생각해보자. 핑퐁버퍼는 DDR에서 들어오는 데이터를 in버퍼로 옮기고, out버퍼에서 DXR로 데이터를 옮기는 형태였다. 데이터의 이동이 2가지 이므로 핑퐁버퍼에 DMA를 사용한다면 하인이 2명이 필요할 것이다. 각각 DDR에서 들어오는 데이터를 옮기는 하인을 A, DXR로 내보내는 하인을 B라고 해보자. A는 언제 데이터를 옮겨야 할까? CPU가 명령을 내렸을 때? 아니다. DDR에 데이터가 들어왔을 때 바로 바로 옮겨야 한다. 따라서 DDR에 데이터가 들어오는 것을 이벤트로 사용한다면 A는 이벤트가 발생하였을 때 데이터를 옮기면 될 것이다. 그리고 핑퐁버퍼의 사이즈만큼 데이터를 옮겼다면(버퍼 하나가 꽉 찼다면) 그 때 CPU에게 인터럽트를 걸면 될 것이다. 이러한 방식은 버퍼의 사이즈가 100이라면 48000분의 100초마다 한번씩 인터럽트가 걸리게 된다. 기존에 매번 인터럽트가 걸리던 것과 비교하면 100배 효율적이라고 할 수 있다. 이러한 방식으로 이벤트를 사용하는 것이 유용할 때가 더 많기 때문에 싱크로나이즈드 무브가 더 많이 쓰인다.
노싱크의 경우에는 아무 채널이나 잡아도 되지만 싱크로나이즈드는 채널마다 각각 할당된 싱크가 있다. 예를 들면 타이머 인터럽트를 하인에게 사용하려 하면 타이머 이벤트를 감지하는 채널이 따로 있는 것이다. 해당 사항은 데이터시트를 보면 나와있다. 사용하고 싶은 이벤트를 담당하는 채널을 찾아 맞추어 써야 하는 것이다.

DMA의 설정은 레지스터를 통해 할 수 있다. 각 채널에 대한 Configuration을 설정해주면 된다. 각 채널은 32비트 레지스터로 이루어져 있다. 이 중 2번째가 소스이다. 여기에 Source address를, Length에 몇 개를 움직일지, Destination에 목적지를 입력해준다. 이 3가지가 가장 기본이다.

기본적인 3가지는 모든 DMA가 지니고 있는 사항이라 한다면 EDMA는 더 복잡하다. Ti의 EDMA외에도 요즘 DMA들은 매우 지능적이다. 예전에 비해 정말 복잡한 구조도 옮길 수 있도록 설계되어있다. 위 사진을 보자. Element, Frame, Block이라는 조금은 생소할지도 모르는 단어가 보인다. 천천히 차근차근 따라가보자. 우리는 데이터를 옮기는 명령을 내리는 중이라는 것을 잊지 말자. 데이터를 옮기려면 어떤 정보가 필요할지 생각해보자. 우리가 옮기려는 데이터는 특정 구역에 존재 할 수도 있고, 특정 패턴을 띄는 데이터들일수도 있다. 한 줄씩 옮기고 싶을 수도 있고 한 바이트씩 건너뛰어가며 데이터를 옮기고 싶을 수도 있다. 이처럼 다양한 요구사항들이 나올 수 있기 때문에 데이터를 덩어리 짓는 명칭이 필요하다. 그것이 바로 Element, Frame, Block이다. Element는 A라고 부른다. 움직이는 데이터의 최소 단위이다. 한번에 움직이고자 하는 데이터의 크기가 A인 것이다. 그리고 이러한 크기를 (Element Size) A Count라는 값을 통해 지정할 수 있다. 카운트는 16비트로 이루어져 2의 16승개수 약 6만5천까지 값을 가질 수 있다.
Element의 집합을 Frame이라고 한다. Frame은 B라고 부른다. 프레임의 크기는 B Count를 통해 나타낸다. 이 Frame의 집합을 Block이라 하며 이는 C로 나타낸다. C도 C Count를 가지고 있다.
모든 DMA의 구조는 하나의 Block이 움직였을 때 끝나는 형태로 만들어져 있다. 만약 100바이트의 데이터를 옮기고 싶다면 A카운트의 크기를 1로 한 뒤 B카운트는 100, C카운트는 1로 설정한다고 해보자. 1짜리 데이터가 100개 모인 프레임이 하나 옮겨진 순간 Block안에는 단 하나의 프레임만 들어있는 형태이므로 Block이 움직였고, 해당 명령은 끝이 난다.
또 다른 방법은 A카운트를 100으로 잡고 B, C카운트 모두를 1로 잡는 것이다. 이러면 100짜리 데이터 하나를 통째로 옮기게 되며 그것이 곧 Block이 되어 해당 명령은 끝나게 된다.

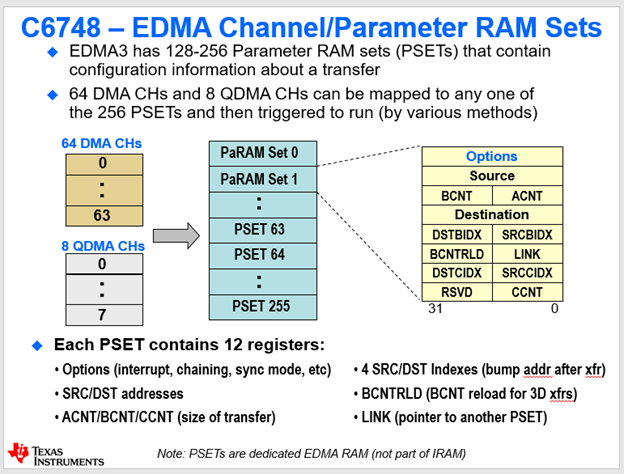
위 사진을 살펴보자. 왼쪽에 채널과 그에 매칭되는 PSET들을 보여주고 있다. 64개의 채널들이 존재한다는 것을 볼 수 있고, 해당 채널들은 PSET63번까지 직접 연결되어있다. 그런데 64번부터 255번까지 PSET이 더 많다…? 더 많은 것은 추가적인 명령을 저장하기 위한 용도이다. 이에 대해서는 나중에 설명하도록 하겠다. 지금 기억할 것은 0~63번의 채널들이 각각 PSET0~63까지 직접 연결되어있다는 사실이다.
따라서 형식에 맞춰 작성한 Configuration설정을 원하는 채널 PaRAMSET에 적절히 넣어주면 해당 Configuration이 동작하게 된다. 해당 Configuration의 DSTBIDX, SRCBIDX, DSTCIDX, SRCCIDX에 대해 알아보자. DST는 Destination이며 SRC는 source이다. 그리고 IDX는 인덱스이다. 인덱스는 무엇일까? 바로 얼마나 건너뛸지에 대한 정보이다. 그런데 A인덱스는 없다. 왜냐하면 A는 무조건 한 묶음이기 때문이다.
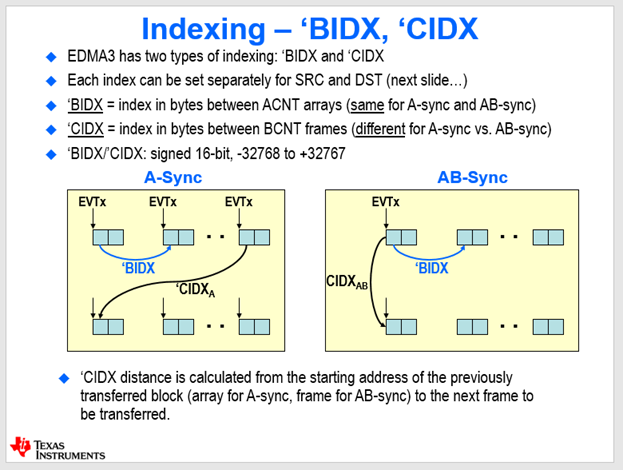
감이 잘 잡히지 않을 것이다. 위 사진을 보면 명확하게 이해되지 않을까 싶다. 위 사진은 데이터를 옮기는 포맷 두 가지를 소개하고 있다. 이것에 대해서는 조금 뒤에 다시 상세히 다루도록 하고 일단 인덱스가 무엇을 의미하는지 보자. 지금 네모 두 개가 바로 엘리먼트이다. 즉, A이다. A카운트는 2일 것이다. DMA는 이 엘리먼트를 B카운트 개수만큼 하나씩 옮길 것이다. 이 때 이전 엘리먼트의 시작점과 다음 엘리먼트의 시작점 사이의 거리가 바로 B인덱스이다. 이해가 되는가?
CIDX도 결국 frame과 frame사이의 간격을 나타낸다. 이 때 CIDX를 나타내는 방식에는 두 가지가 존재한다. 이에 대해서는 뒤에 자세히 설명하도록 하겠다.
중요한 것은 인덱스가 무엇인지 이다. 엘리먼트들의 간격이 바로 BIDX이고 프레임의 간격이 CIDX인것이다. 이 개념을 기억해두도록 하자.

뭐든지 예시를 통해 보면 그 개념이 쉽게 이해된다. 예시를 살펴보자. 데이터를 사진과 같이 움직이고 싶다. 이 때 Configuration은 다음과 같이 작성한다. Source에 시작 어드레스 넣어주고 옮기고자 하는 메모리의 주소를 Destination에 넣어준다. 그리고 난 뒤 A카운트를 4로 설정하고 B, C 둘 다 1로 설정하여 원하는 데이터를 통짜로 옮길 수 있다. 이 때 엘리먼트가 하나이므로 인덱스는 필요 없다.

하지만 만약 Element를 1로 설정할 경우 엘리먼트를 옮긴 다음에 다음 인덱스를 어떻게 정해야 할지 생각해야 하므로 B인덱스를 1로 정의해야 한다. 즉, A를 한 칸씩 옮길 것이기 때문에 SRCBIDX가 1이 되어야 하고, 넣는 값 또한 한 칸씩 이므로 DSTBIDX도 1인 것이다.

조금 더 특수한 경우를 생각해보자. 이번에는 메모리가 건너뛰어져서 옮겨야 하며 저장할 때도 두 칸씩 건너뛰어지며 쌓는다.
이 때 A Count는 1로 할 수밖에 없다. 그리고 B는 4로 잡아서 4개를 한 묶음으로 보자. 즉 프레임 하나에 엘리먼트 4개가 들어간 형태가 되는 것이다. 그리고 CCNT는 1로 하여 해당 프레임을 전체 블락으로 설정하였다.
소스 B인덱스는 6칸씩 건너뛰고 있다. 따라서 그 값은 6이 되어야 한다. 반면 DSTBIDX는 2칸씩 건너뛰며 저장하고 있기 때문에 2 값을 가진다.
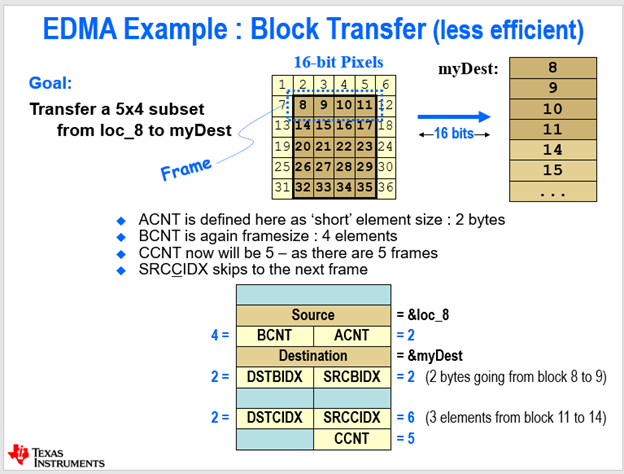
더 복잡한 형태의 이동을 생각해보자. 이번에 옮기고자 하는 데이터는 16비트 픽셀이기 때문에 네모 하나가 2바이트이다. 따라서 A카운트는 2이다. A 4개를 한 Frame으로 만들어야 하므로 B카운트는 4이고, 그런 B가 5개가 있으므로 C카운트는 5이다.
B인덱스는 Source와 Destination 둘 다 작은 네모 하나가 2바이트이므로 2씩 증가해야 할 것이다. C인덱스는 프레임 끝난 뒤 적용되는 인덱스이다. 소스에서 첫 줄을 보면 11에서 14로 가야 하는데 그러면 3번의 이동이 필요하며 하나당 2바이트이므로 총 6바이트이다. 따라서 SRCCIDX는 6이다. 이에 반해 DSTCIDX는 그대로 2바이트이다.

그런데 사실 옮기고자 하는 데이터 4개가 이어져있기 때문에 통째로 엘리멘트로 설정할 수 있다.
엘리멘트를 8바이트로 설정하고 프레임이 5개 있으므로 B카운트 5, 블락은 하나이므로 C카운트는 1로 할 수 있다. 이 때는 소스B인덱스가 8에서 14로 갔기 때문에 6*2 = 12가 되어서 SRCBIDX는 12이다. DSTBIDX는 4칸씩이므로 8씩 증가하면 될 것이다.
이처럼 형태가 복잡할 때는 C까지 사용해야 하지만 연속된 엘리멘트가 있다면 프레임만으로도 끝낼 수 있다.
(이거 누가 설명해주지 않으면 일주일정도 걸린다... 개념이 없이 보면.. 유저 가이드 가지고 보면 뭐가 핵심적인지 알 수 없다.. 다 봐도 모른다)

이제 아까 잠깐 언급하고 넘어간 이야기를 해보자. 지금 우리가 이야기하고 있는 데이터 전달은 싱크로나이제이션 무브이다. 그리고 이 싱크로나이제이션에는 A싱크와 AB싱크 2가지가 있다. 사실 엄밀히 말하자면 DMA의 무빙은 모두 싱크로 이루어진다. no싱크도 사실 싱크의 일종이다. CPU가 하인에게 명령을 내리면 하인이 일을 하기 위해서는 반드시 싱크가 있어야 한다. 이 때 싱크는 바로 이벤트이다. 명령을 받고 난 뒤 이벤트가 있어야 하인이 움직인다. 이것이 대전제이다.
그럼 노싱크는 이벤트가 없을 텐데 어떻게 작동할까? 바로 노싱크는 하인에게 명령을 내리고 난 뒤에 CPU가 직접 이벤트를 준다. 따라서 이벤트 한번에 다 움직일 수 있도록 명령서를 짜야 한다.
다시 싱크로나이제이션으로 돌아와서, A싱크는 이벤트가 발생했을 때 하나의 엘리멘트가 움직이는 형태이다. 10개의 엘리멘트를 움직이려면 10번의 이벤트가 필요한 것이다. 모든 엘리멘트의 수만큼 이벤트가 필요하기 때문에 그림상의 블락 전체를 움직이려면 B카운트 * C카운트의 수만큼 이벤트가 필요하다. 이 때 이벤트는 CPU가 주는 것이 아닌 외부에서 계속하여 들어오는 이벤트이므로 대부분의 경우 A싱크모드를 사용한다.

에 반해 AB싱크는 이벤트 하나에 하나의 프레임이 움직인다. 그게 끝이다. 그리고 그로 인해 전에 언급한 차이점이 발생한다. 바로 인덱싱이다.

A싱크와 AB싱크의 C인덱스의 정의를 잘 보자. 조금 다르게 정의되어있다. AB싱크는 프레임단위로 움직이기 때문에 프레임을 건너뛰는 값을 증가분으로 가진다. 즉 AB싱크는 CIDX값으로 프레임의 시작부분에서 다음 시작부분까지의 차를 지닌다는 것이다. 이러한 차이점에 대해서는 뒤에서 코드를 통해 더욱 자세하게 다루도록 하겠다.

이전에 인터럽트에 대해 자세한 설명을 한 적이 있다. 그리고 그 설명들은 인터럽트 세팅과 관련된 코드에 상세히 녹아 들어갔었다. 이번에도 같다. DMA와 관련된 레지스터들을 알아야 한다. 그래야 원하는 동작을 작동시킬 수 있을 것이다.
앞에서 언급하였듯이 모든 채널은 이벤트와 관련된 채널들이 있다. 각각의 채널들은 자신이 담당하고 있는 이벤트를 감지한다. 그렇다면 어떤 방식으로 이벤트들을 감지할까? 위 사진은 이벤트가 발생되는 3가지 경우를 보여준다.
1번에 보이는 McASP0는 우리 예제와 같다고 생각해도 된다. 사진에서 말하는 것은 이것과 연결된 채널이 3번으로 고정되어있다는 것이다. 이 때 이벤트가 발생하면 ER 즉 이벤트 레지스터가 세트가 된다. 내부에서 자동으로 설정되는 것인데 이벤트가 발생하면 해당 레지스터가 1로 설정되는 것이다. 그리고 난 뒤 자동으로 지워진다. EER은 Event Enable Register이다. 이것을 통해 사용자가 이벤트를 컨트롤 할 수 있다. 일종의 문이다. 이걸 닫아두면 이벤트의 전달이 되지 않는다. 즉, 외부에서 데이터가 들어와 ER을 1로 만들었고, 이 때 EER또한 1이었다면 이벤트가 전달된다.
2번 그림의 ESR은 Event Set Register이다. 해당 레지스터는 CPU가 강제로 이벤트를 발생시킬 때 쓰는 것이다. 노싱크의 경우 CPU가 직접 이벤트를 발생시켰었다. 그런 경우 CPU는 ESR을 통해 이벤트를 발생시킨다.
3번 체인기능은 뒤에 코드와 함께 설명한다.
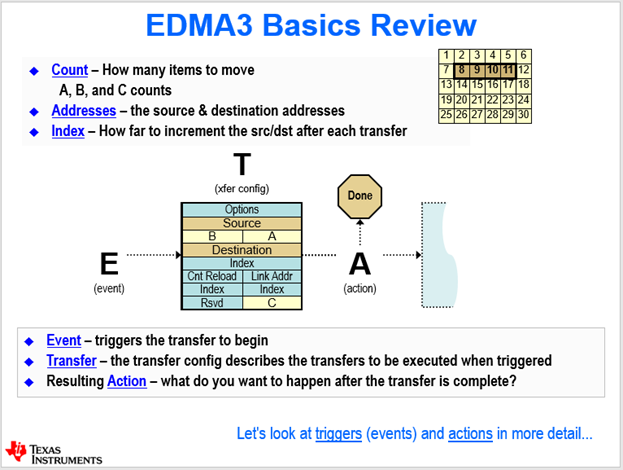
자. 이 그림을 통해 정리를 해 볼 수 있을 것이다. 앞에서 설명한 방식으로 이벤트가 발생되면 해당 채널에 존재하는 config를 통해 DMA가 동작할 것이다. Count, Address, Index, Event 등등에 대한 간략한 소개를 하였다. 이제 남은 것은 Options와 Cnt Reload, Link Addr, Rsvd일 것이다. 다른 것들은 뒤로 밀어두고 먼저 Options를 자세히 살펴보도록 하자.

이 Options에는 바로 채널 명을 명시하는 TCC라는 항목이 들어가 있다. 채널 명을 명시한다고 표현하였지만 정확히는 인터럽트와 밀접한 관련이 있는 역할을 담당한다.
(참고로 Options 뒷부분에는 A 또는 AB 싱크를 사용한다는 내용이 들어간다.)

위의 그림을 보자 채널이 총 64개가 있다. 하인이 64명이 있는 것이다. CPU는 하인에게 일을 시킨다. 그런데 시킨 일이 다 끝나면 끝냈다고 알려야 하는 일들이 있을 수도 있다. 그러한 일들을 설정 할 수 있는 것이 TCC라고 할 수 있다.
Options의 20번째 비트는 TCINTEN으로 해당 비트가 1이면 일이 끝난 뒤 CPU에게 알리겠다는 의미를 지닌다. CPU에게 알리는 방식은 바로 인터럽트이다. 잠깐, 여기서 이런 의구심이 들어야 한다. 인터럽트는 제한적인 사용이 가능했었다. 우리가 사용할 수 있었던 인터럽트는 128개였다. 그런데 EDMA의 채널 64개를 모두 사용하여 인터럽트를 사용한다면 128개 중 무려 64개의 인터럽트를 EDMA를 위해 사용해야 하는 것인가? 물론 아니다. 이러한 일을 방지하기 위하여 64개의 채널들은 모두 하나의 인터럽트로 묶여져 있다. 64개의 채널들 중 하나라도 TCINTEN의 값이 1이여서 일을 마친 뒤 인터럽트를 발생시키면 EDMA3CC_INT라는 인터럽트가 CPU에게 전달된다. 그러면 어떻게 어떤 채널에서 발생한 인터럽트인지 구별할 수 있을까? 바로 IPR을 통해 그 일을 할 수 있다. IPR은 Interrupt Pending Register이다. Options에는 TCC를 입력하는 칸이 있다. 해당 입력 값에 따라 그 채널과 IPR을 연결 할 수 있다. 대부분의 경우 TCC는 채널 넘버로 설정한다. 하지만 그것이 강제되는 것은 아니다. 원한다면 0번 채널을 3번 IPR에 연결해둘 수도 있다. 물론 그러는 것은 정말 좋지 않은 스타일인 것 같다. 과거 멀티테스킹을 할 때 비어있는 채널을 돌리기 위해 이런 식으로 만들어 두었다고 한다.
이렇게 TCC를 통해 각 채널과 이어진 IPR에 작업 종료 시 1을 쓰고, 인터럽트를 발생시키는 것이다. CPU는 역으로 IPR을 확인하여 어느 채널에서 인터럽트가 발생하였는지 알 수 있다. 이 때 유저는 각 채널 별 IER 즉 Interrupt Enable Register를 통해 그 채널의 인터럽트를 CPU에게 전달시킬 것인지 아닌지 결정할 수 있다.
LAB6
열심히 배웠다. 이제 이론을 활용하여 코드를 작성해보자. 가장 기본적인 Memory move를 먼저 할 것이다.
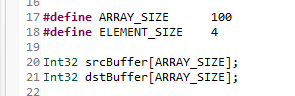
100 크기의 배열을 선언한다. 배열은 integer 배열이다. 따라서 앨리먼트 사이즈는 int32의 크기인 4가 될 것이다.

이 함수는 srcBuffer에 적당한 값을 넣어주는 용도로 만든 함수이다. 안에 들어가는 값은 의미 없는 값들이다.

우리는 EDMA를 활용하여 데이터를 옮길 것이다. 옮긴 뒤 제대로 옮겨졌는지 확인하는 함수이다.

관련된 레지스터를 초기화 해준다. 사실 전원 리셋으로 리셋 되기 때문에 없어도 되지만 프로그램을 돌리고 재 로드하는 과정에서는 리셋이 안될 수도 있다. 재로드 시 리셋은 웜리셋이라하여 일부 레지스터들이 초기화가 안 된다. 따라서 코드로 직접 초기화를 해주는 부분을 만들었다.
레지스터 이름을 살펴보자.
ECR
이벤트가 발생하면 세트가 되는 ER(Event Register)은 유저가 세트하지 않고 내부에서 자동으로 세트되고 클리어된다고 했다. 이 ER은 32비트짜리 레지스터이다. 각각의 비트는 채널에 매핑되어 있다. 만약 이걸 지우고 싶으면 ECR 이벤트 클리어 레지스터를 통해 지울 수 있다. 지우고 싶은 채널과 매핑되는 비트에 1을 쓰면 ER이 0이 된다.
EESR, EECR
EER (Event Enable Register)은 일종의 게이트이다. DMA를 쓰려면 보통 다 인에이블 시켜놓는다.
이걸 디스에이블 시켜놓으면 이벤트 자체가 작동을 안 한다. 얘도 유저가 직접 건들이지 못한다.
EESR, EECR은 Event Enable Set Register / Clear Register 이다. 마찬가지로 채널과 매핑되어 있으며 EESR에 맞는 위치에다가 1쓰면 EER이 1이 되고 EECR에 1을 쓰면 EER이 0이된다.
ICR
IPR(Interrupt Pending Register)에 대해 위에서 언급하였었다. ICR은 그 IPR을 지운다. 처음 시작할 때는 지워주는 것이 좋다. 물론 IPR이 1이라하여도 IER이 1이 아니면 인터럽트가 전달되지 않을 것이다.
IECR
그게 IECR이다. Interrupt Enable Clear Register. IER을 0으로 바꾼다.

메인문을 살펴보자. 배열에 데이터를 만들어 넣은 뒤, EDMA를 초기화 시킨다. 그러고 나면 SetupEDMA3라는 함수가 눈에 띈다. 이 함수를 통해 우리는 명령서를 하인에게 전달할 것이다.
(주소는 정수로 캐스팅 할 수 있다. 배열의 주소를 캐스팅하여 인수로 넘긴 것이다.)
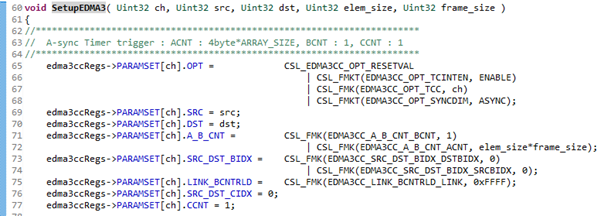
자, 이제 위에서 열심히 배운 이론적인 내용이 보인다. 각 채널에 해당하는 PSET에 명령서가 저장된다고 했었다. 이에 맞게 우리는 5번 채널을 사용할 것이고, PARAMSET[5]에 명령서를 작성할 것이다. 명령서는 비트단위의 비트연산자와 매크로를 이용하여 작성하였다.
OPT에는 TCINTEN을 ENABLE(1)하여 인터럽트를 전달하도록 하였고, TCC는 5번으로 설정하였다. 따라서 수행이 다 끝나면 IPR 5번에 1이 작성될 것이다. 우리는 ASYNC를 사용할 것이다.
SRC에는 소스 즉, 옮기고자 하는 데이터의 주소가 들어가면 된다. 배열의 주소 값을 넣었다.
DST에는 목적지 즉, 옮기려 하는 곳의 주소가 들어가면 된다. Sdt 배열의 주소 값을 넣었다.
A_B_CNT에는 카운트 값을 작성하였다. 지금은 한번에 모든 데이터를 옮기려 하였기 때문에 A카운트 값을 전체 데이터의 값으로 설정하고, B카운트 값은 1으로 작성하였다.
따라서 당연히 SRC인덱스들은 다 0일 것이다. C카운트 또한 당연히 1일 것이다.
LINK에 대해서는 나중에 설명하도록 하겠다.

만약 AB싱크를 사용한다면 A카운트를 엘리먼트 사이즈로, B카운트를 배열의 크기인 frame사이즈로 설정한 뒤 B인덱스는 소스와 dst 둘다 엘리먼트 사이즈가 될 것이다. AB싱크는 이벤트 한 번에 프레임이 다 넘어간다는 사실을 잊지 말자.
이제 필요한 것은 무엇일까? 바로 이벤트이다! 말했다시피 DMA는 이벤트가 있어야 동작을 한다. 이벤트를 발생시키는 Task를 하나 만들자.

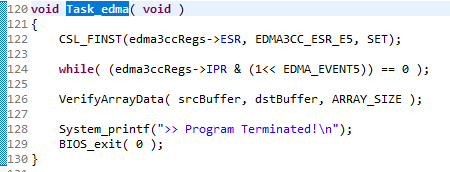
CSL_FINST(edma3ccRegs->ESR, EDMA3CC_ESR_E5, SET); 이 줄을 자세히 보자. ESR의 5번째를 세트시킨다. 즉, 5번 채널에 이벤트를 만드는 것이다. 그 순간 이벤트는 발생할 것이고, 우리가 넣어둔 명령서에 의해 DMA는 작동할 것이다. 그리고 작동이 끝나면 IPR에 5번 에다가 1을 쓴 뒤 인터럽트를 발생시킬 것이다. 지금은 그러한 인터럽트를 사용하지는 않고 있기 때문에 단순히 while( (edma3ccRegs->IPR & (1<< EDMA_EVENT5)) == 0 ); 이 코드를 통해 IPR 5번째의 상태를 검사한다. 만약 해당 비트가 1이 된다면 while문을 빠져나올 것이고 정상적으로 옮겨졌는지 검사한 뒤 데이터 이동이 문제없이 끝났다면 Program Terminated를 출력할 것이다.

이렇게 말이다.
LAB6_A
자 그럼 이제 사용하지 않았던 인터럽트를 사용해보자. 방금 코드는 CPU가 해당 비트를 계속하여 모니터링 하고 있기 때문에 CPU는 다른 일을 하지 못한다. 따라서 인터럽트를 이용하는 것이 좋다. 데이터의 이동이 끝나면 IPR가 1이 되는 것도 맞지만 EDMA이름의 인터럽트 또한 발생한다. 데이터 시트를 살펴보자.

8번을 보면 EDMA3_0_cc0_INT1이라는 이름의 인터럽트가 있다. 우리는 해당 인터럽트를 사용해야 한다. 따라서 event id는 8번인 인터럽트를 하나 만들자.

우선 간단한 코드로 인터럽트 사용을 해보자. 단순하게 변수 하나를 확인하는 방식으로 함수를 짜 보았다.


기존에 IPR을 살펴보던 코드는 edma_done을 체크하는 방식으로 바뀌었다. 이러면 cpu가 변수확인을 계속한다는 점에서 기존과 똑같지만 인터럽트를 사용한다는데 관심을 가져보자.
코드에 대한 설명을 하자면 volatile int edma_done = 0; 을 쓴 이유는 volatile을 하지 않으면 컴파일러 입장에서는 이 변수가 쓰이지 않는다고 판단하여 Task단에서 while문을 못빠져 나간다고 판단, 뒤의 코드를 지울 수도 있다. 컴파일러가 코드를 기계어로 바꿀 때 최적화를 하는데, 이 때 코드의 변경이 일어날 수 있다. 이러한 과정에서 예기치 않은 코드의 변화를 막는 용도라고 생각하면 된다.
IER을 enable 해야 한다. 6번 인터럽트를 활성화 시키자.
CSL_FINST(edma3ccRegs->IESR, EDMA3CC_IESR_I5, SET); 5번비트를 세트한다.
CSL_FINST(edma3ccRegs->DRA[CSL_EDMA3_REGION_1].DRAE, EDMA3CC_DRAE_E5, ENABLE);
보드 안에 코어가 ARM도 있고 DSP도 들어있다. 근데 EDMA는 둘 다 사용이 가능하다. REGION_1이라는 것은 이벤트를 DSP에 전달하라는 의미를 가지고 있다. DSP하고 ARM이 동시에 돌아가기 때문에 각각의 채널을 각각의 코어에 전달할 수 있는 것이다. 멀티코어이기 때문에 가능하다.
자 이제 동작시켜보자. 잘 된다!
LAB6_A1
이번에는 주기적인 이벤트에 의해 DMA가 움직이는 그런 상황을 한번 만들어 볼 것이다. 물론 앞으로 할 것은 리시브를 가져다 쓸 거지만 연습 삼아 peripheral로 타이머를 사용하자. 타이머 이벤트를 1초로 주면 DMA는 1초에 한번씩 움직이게 될 것이다.

Timer는 예전에 사용한 코드를 조금 고쳐 사용한다. 기존 타이머에서는 Timer.c 레지스터 시작주소부터 시작해서 구조체의 포인터를 가지고 동작하였는데 TMR_1은 sys/bios에서 내부 클럭을 사용한다. 그래서 유저가 쓰려면 0으로 바꿔야 한다. 유저 클럭으로 TMR_0를 사용하는 것이다.
어찌 되었든 타이머를 작동시켰다. 이 타이머를 이벤트로 받아와야 한다. 따라서 이제 담당 하인을 찾아야 한다. 타이머를 받아올 채널을 찾아야 하는 것이다. 어떤 채널이 어떤 이벤트를 담당하는지는 데이터시트에 나와 있다.

데이터시트 101쪽을 보면 이벤트 10번에 타이머가 있다. 즉 10번 채널이 (11번도) 타이머를 담당하는 것이다.

따라서 메인문 안에 SetupEDMA3함수 인자로 EDMA_EVENT10을 넘겨야 한다. 또한 함수 내용도 조금 수정해야 한다. 이제는 EER을 신경 써야 하기 때문이다.

A싱크를 쓰자. 4바이트 짜리를 20개 움직이게 해보자. ELEMENT_SIZE도 적절히 넣어주자.
CSL_FINST(edma3ccRegs->EESR, EDMA3CC_EESR_E10, SET); 은 EER을 셋한다. IPR은 모든 트랜스퍼가 끝났을 때 1이 된다. 타이머가 작동할 때마다 데이터이동이 동작한다. 동작시키면 시간이 꽤 지난 후에 데이터 이동이 완료되는 것을 볼 수 있을 것이다.
LAB6_B
EDMA를 조금 더 효과적으로 사용해보기 위해 이미지를 사용할 것이다. 이미지는 256*256 사이즈의 흑백이미지를 1차원 배열에 넣어 만들었다.


위 사진처럼 256*256 사이즈의 배열을 만들고 거기에 각 픽셀 값을 넣은 1차원 배열을 활용할 것이다. 이를 위해서 해당 이미지를 DDR에 저장하기 위해 다음과 같은 파일을 만들어준다.

우선 그림을 올려둘 캔버스를 만들자.

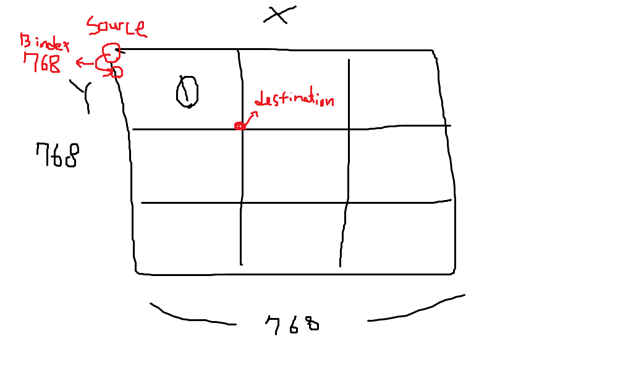
Uint8 image[PIXELS_IN_IMAGE]; 이 코드는 768*768이다. X_SIZE와 Y_SIZE 모두 256이며, 우리가 사용할 캔버스는 가로 세로 각각 3배씩 된 768*768 사이즈를 사용할 것이다.
그림으로 표현하자면

1번 표시를 한 곳에 이미지를 넣을 것이다.

위 코드에 puts() 부분에서 stop을 하여 이미지를 살펴보자.

멈춰져 있는 상태로 Tools – Image Analyzer을 들어가면 이미지 창이 뜬다.

이미지 창에서 우 클릭을 하여 Properties에 들어간다.

이렇게 설정을 해준다. 그리고 이미지를 새로고침한다. (우클릭-refresh)

그럼 이런 이미지가 뜬다.
저기있는 이미지는 맨 처음 연구자가 사용한 이미지이다. 그런데 그 정체가 무려 성인잡지 모델이라고 한다. 원본사진은 전신나체 뒤 태이다...ㅎ 나중에 이미지 프로세싱 학회에서 이분 모셔서 공로상을 줬다고 한다. 레나 이미지라 검색하면 더 자세한 이야기가 나온다.
우리는 저 이미지를 EDMA를 사용하여 옮길 것이다. 가운데로 옮겨보자.
소스어드레스를 가장 왼쪽 상단으로, Dst address를 표시한 지점으로 설정해야 할 것이다. 그리고 AB싱크 써서 한 프레임씩 옮길 것이다. 256을 엘리먼트로 잡고(A카운트) 엘리먼트 256개를(B카운트) 움직일 것이다. 이 때 소스의 B인덱스는 768이다. 매번 768씩 증가해야 하기 때문이다.
이건 Destination도 마찬가지이다. 코드로 작성하면 다음과 같다.

코드를 돌려보면 이런 결과물을 얻는다.

사진이 가운데로 옮겨졌다!
가운데 뿐 아니라 모든 곳에 옮기려면 Destination의 위치를 적절히 바꿔가며 7번 더 반복하면 될 것이다.

이런 식으로 i값과 j값에 따라 그 Destination의 위치를 변경하도록 만든 뒤,

2중 for문을 통해 i와 j에 0에서 2까지의 값을 넣어주면 화면 가득 사진이 복사될 것이다. 다음과 같이 말이다.

LAB6_C
단순한 사진의 이동은 EDMA의 기능을 적극적으로 사용하지 못한다. 조금 더 복잡한 기능을 요하는 축소를 한번 해보도록 하자. 사진을 1/4 사이즈로 줄인다고 생각해보자. 어떻게 옮겨야 할까? 픽셀들을 다 옮기는 것이 아닌 하나씩 건너뛰어가며 옮기면 될 것이다. 이는 Source단에서 설정을 잘 해주면 될 것이다.

다시 복습해보자. B카운트는 엘리먼트가 프레임에 몇 개나 들어있는가 이다. 그리고 그런 프레임이 몇 개가 있는지는 C카운트였다. 사진 축소를 위해서는 소스의 B인덱스를 2로 하면 픽셀을 하나씩 건너뛰게 된다. C인덱스는 PIXELS_PER_LINE*2으로 하여야 한다. 그래야 한 줄씩 건너뛸 것이다. 이제 이걸 코드로 옮기기만 하면 된다?? 아니다! 이건 움직일 수가 없다...! 왜일까? 바로 이벤트 때문이다. AB싱크에서는 이벤트 한번에 한 프레임이 간다고 말했었다. 따라서 전체 블록을 옮기기 위해서는 이벤트를 128번 줘야 할 것이다. 이는 실용적이지 않다.
이를 해결하기 위해 chain기능을 사용할 것이다.

이전에 이벤트를 발생시키는 방식들 중 1번과 2번에 대해서는 다뤘다. 그러나 3번은 넘어갔었는데 이 체인에 대한 내용을 지금 설명하도록 하겠다.
CER은 DMA 채널 자체가 만들어 낸다. 채널에게 다른 채널을 트리거 시킬 수 있도록 만들 수 있다. 즉 자신의 일을 끝내면(프레임을 하나 보내면) 이벤트를 발생시킬 수 있는 것이다.

축소시키는 코드를 보며 체인에 대해 설명하도록 하겠다. 이전엔 보지 못했던 한 줄이 OPT에 추가된 것을 볼 수 있을 것이다. CSL_FMKT(EDMA3CC_OPT_ITCCHEN, ENABLE) 이것이 바로 새롭게 추가된 항목이다. 기존에 언급했던 TCC는 Transfer Complete Chain의 약자이다. TCC는 모든 이동이 다 끝난 뒤에 작동한다. 만약 TCC가 5번이라면 모든 Transfer가 종료되면 IPR 5번에 1을 기록한다고 하였었다. 이 때 설정하는 이 TCC값은 이처럼 모든 Transfer가 종료된 시점에서 사용되는 것 외에도 또 한가지 사용 방식이 있다. 바로 ITCCHEN에 의한 이벤트 발생이다. ITCCHEN을 ENABLE하면 A싱크에서는 엘리먼트가 움직일 때마다 이벤트가 발생하고 AB싱크에서는 프레임이 다 움직일 때마다 이벤트가 발생한다. 이 때 이 이벤트는 TCC에 정의되어있는 채널로 향한다. 만약 5번 채널의 TCC값이 5라면 셀프 이벤트를 계속하여 발생시킬 수 있는 것이다. 이 때 가장 마지막인 모든 Transfer가 종료된 순간에는 이벤트가 발생하지 않는다는 점을 유의하자.

위의 코드를 통해 사진의 크기를 줄이는 코드를 반복시킬 수 있다. 그 결과 다음과 같은 사진이 나온다.
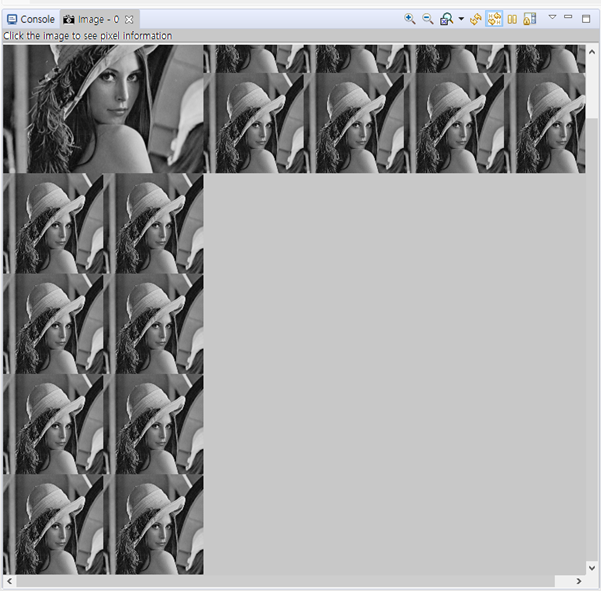
우측 아래 커다랗게 빈 공간이 보인다. 저 공간은 사진을 확대하여 집어넣어 보기 위해 남겨 두었다.
LAB6_D
확대는 어떻게 해야 할까? 쉽다! 4번 옮기면 된다. 이 때 한번 옮길 때 한 칸씩 띄어가며 옮겨주면 될 것이다.
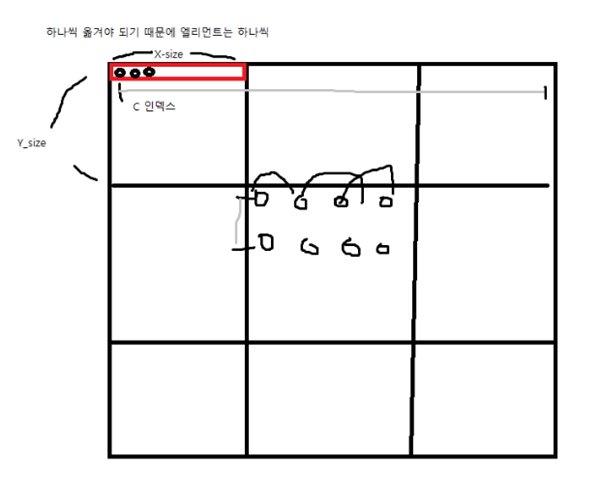
위 그림과 같이 옮기는 것을 시작 지점을 다르게 하여 총 4번 반복하면 될 것이다. 이는 Destination address를 바꿔가며 해결하면 된다.

offset이라는 변수를 선언했다. 해당 변수는 도착지점을 변경해준다. 하나씩 옮겨야 하기 때문에 A카운트는 1이고 한 줄을 frame으로 잡을 것이기 때문에 B카운트는 X_SIZE이다. 그러한 frame이 Y_SIZE 개수 만큼 있으므로 C카운트는 Y_SIZE이다.
소스에 대해서는 엘리먼트는 하나씩 증가한다. 따라서 소스B인덱스는 1일 것이다. 또한 C인덱스는 AB싱크이므로 frame의 시작점과 시작점의 차이만큼일 것이다. 이는 PIXEL_PER_LINE이다.
데스티네이션에 대해서는 한 칸씩 띄어줘야 하기 때문에 B인덱스는 2일 것이다. 또한 세로로도 한 칸씩 띄어주어야 하므로 C인덱스는 PIXEL_PER_LINE의 두 배일 것이다.
이러한 코드에 대해 offset은 총 4가지가 나올 것이다. 첫 번째로는 0, 두 번째는 1, 세 번째는 PIXEL_PER_LINE, 네 번째는 PIXEL_PER_LINE+1 이다.
이제 이걸 4번 반복하여 또는 4개의 채널을 사용하여 작동시키기만 할 것이다. 그런데 일일이 CPU가 해줘야 한다. 명령을 4번 내려야 하는 것이다. 이러한 방식을 조금 더 향상시킬 수 있는 방법이 존재한다. 바로 링크이다.
이 사진을 다시 살펴보자.
제공되는 DMA 채널은 64개이다. Ch0~ch63까지 채널이 있고 각각의 채널은 PSET이라는 메모리를 4바이트씩 가지고 있다. 이 메모리에 명령서를 넣으면 해당 채널이 그 명령대로 작동하는 방식이었다. 그런데 명령서를 저장할 수 있는 공간은 256개가 있다. 어떻게 된 일일까? 이 추가적인 공간들은 채널은 하나만 사용하는데 명령을 여러 개 내리고 싶을 때, 여러 개의 명령서를 한꺼번에 넘긴 뒤 알아서 수행하도록 할 수 있도록 만들어진 공간이다. 여러 개의 명령서들이 서로를 찾아내는 방법은 바로 LINK라는 저 부분이다


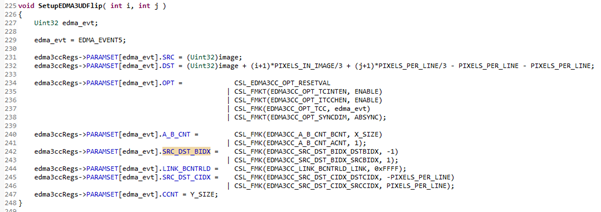
링크를 사용한 함수이다. 직관적인 이해를 돕기 위해 같은 코드를 여러 번 복사하여 붙여넣었다.
코드가 길고 복잡하다. 하지만 지금 말하는 부분은 이 부분이다.




기존 코드들은 저 링크 부분이 항상 0xFFFF로 되어있었다. 그러나 지금은 각각의 명령서들이 서로 다른 링크를 가지고 있다. 사실 모든 DMA의 명령어는 다 링크되어있다. 링크가 되지 않은 명령은 없다. 수많은 링크들 중 0xFFFF는 그 링크를 끝낸다는 의미를 지닌다. 즉, 링크가 되지 않았다는 의미의 주소를 링크시켜 링크를 안 시키는 것이다.
즉, 링크는 해당 명령이 끝난 뒤 이어지는 다음 명령을 가르킨다. 그런데 한가지 짚고 넘어가야 할 일이 있다. 기존 시스템을 잘 생각해보면 chain 기능을 사용하여 자기자신에게 지속적으로 이벤트를 발생시켜 DMA가 연속적으로 동작하였었다. 그리고 한 블록 전체의 이동이 끝나면 이벤트를 발생시키지 않았었다. 따라서 그러한 동작방식에 의해 링크된 명령으로 옮겨간다 하여도 이벤트가 없기 때문에 해당 명령은 동작하지 않을 것이다. 따라서 CSL_FMKT(EDMA3CC_OPT_TCCHEN, ENABLE) 이 항목을 추가시켜주어야 한다. TCCHEN을 활성화 시키면 마지막 transfer에서도 이벤트가 발생하게 된다. (물론 모든 명령서의 끝인 마지막 명령 – 지금은 8번 –에서는 비활성화 시켜야 할 것이다.)
PSET에 남는 공간이 많다고 이야기 하였지만 꼭 남는 부분만 사용 가능한 것이 아닌 원한다면 안 쓰는 채널의 명령서 공간을 사용해도 상관없다. 지금 코드는 쓰지 않는 6, 7, 8번 공간에 명령서를 집어넣은 상태이다. 이 코드를 사용하면 5번 채널 하나만을 사용하여 데이터를 옮기게 된다. 채널이 많이 남는데 굳이 하나만 사용해야 할 필요는 없다. 원한다면 5, 6, 7, 8번 채널을 모두 활성화 시킨 후 동시에 사용해도 된다. 하지만 실제로는 연속적인 링크 형태가 더 유용한 경우가 많기 때문에 링크에 대해 개념을 숙지하고 사용할 줄 알아야 할 것이다.

결과물을 보면 원본 사진이 확대된 것을 볼 수 있다. 이 정도면 EDMA의 대부분 기능을 사용하였다. 이보다 더 복잡한 것은 많지 않을 것이다. 이제 몇 가지만 더 해보자. 우리가 배운 기능을 활용하면 다음과 같은 코드도 작성할 수 있을 것이다.
이 코드는 어떻게 움직일까? 생각해보자. 정답은 180도 회전을 시킨 모양을 가질 것이다. 위아래로 뒤집었고, 좌우로 뒤집었다. 결과물은 직접 돌려보길 희망한다.
잊지 말아야 할 것은 우리는 핑퐁버퍼에서 EDMA을 활용하고자 했다는 것이다. DMA가 데이터의 이동을 담당해주면 인터럽트가 줄어들고, CPU가 제 성능을 제대로 뽑아올 수 있다. 기존 핑퐁버퍼에다가 DMA를 쓰면 성능이 대략 50퍼센트 가량 증가할 것이다. LAB7에서는 DMA를 사용해서 얼만큼 효과적으로 작동시킬 수 있는지 알아보도록 하겠다.
'DSP' 카테고리의 다른 글
| TMS320C6748 을 활용한 DSP_ FIR&IIR (LAB8) (0) | 2021.02.03 |
|---|---|
| TMS320C6748 을 활용한 DSP_EDMA&McASP (LAB7) (1) | 2019.11.27 |
| TMS320C6748 을 활용한 DSP_ 오디오 (LAB5) (0) | 2019.10.21 |
| TMS320C6748 을 활용한 DSP_ SYS/BIOS Interrupt (LAB4) (0) | 2019.10.03 |
| TMS320C6748 을 활용한 DSP_ SYS/BIOS 설치 (LAB3) (12) | 2019.10.03 |