이 시리즈의 최종목표인 Transformer 하면 빠뜨릴 수 없는 녀석이 바로 attention이다. 이놈의 어텐션은 이곳 저곳에서 끊임없이 등장한다.
그도 그럴것이 매우 직관적인 개념이며, 핵심적인 녀석이기도 하기 때문이다.
오늘은 한번 이 어텐션에 대한 대략적인 개념을 알아보자.
우선 글을 작성하기에 앞서 이 글은 CV를 전공하는 사람이 작성한 NLP 글임을 밝힌다. 개념을 이해하는 것이 주 목적이며 따라서 설명의 편의를 위해 다소 주관적인 해석이 들어있을 수 있다. 또한 CV 관련 내용이 포함되어 있을 수 있다.
자 저번 글에서 설명했었던 RNN을 다시금 떠올려보자.
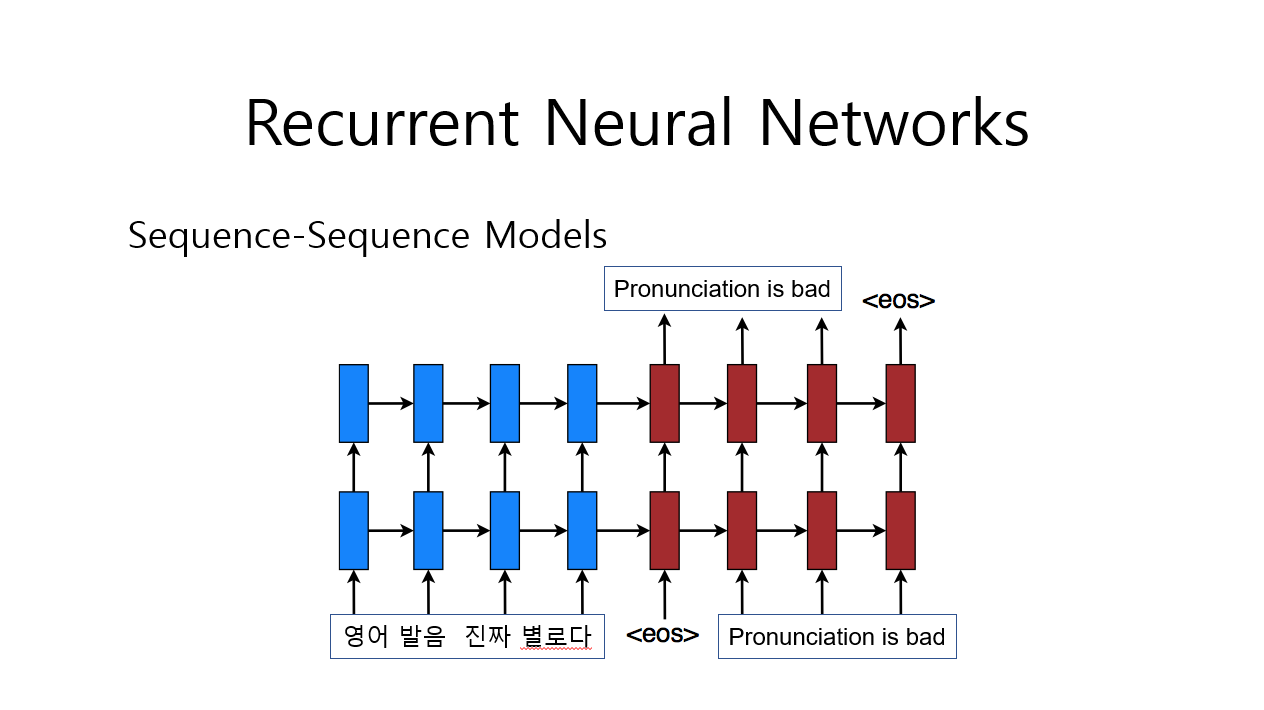
번역을 해 주는 RNN이 있다고 해보자. 이녀석은 입력받은 단어들의 과거 정보들을 지속적으로 옆으로 전달시켜 준다. 위 사진을 자세히 보면 파란 색 부분에서 옆으로 값들을 전달하는 것을 볼 수 있다.
사실 RNN 구조는 다양하게 적용 될 수 있다.
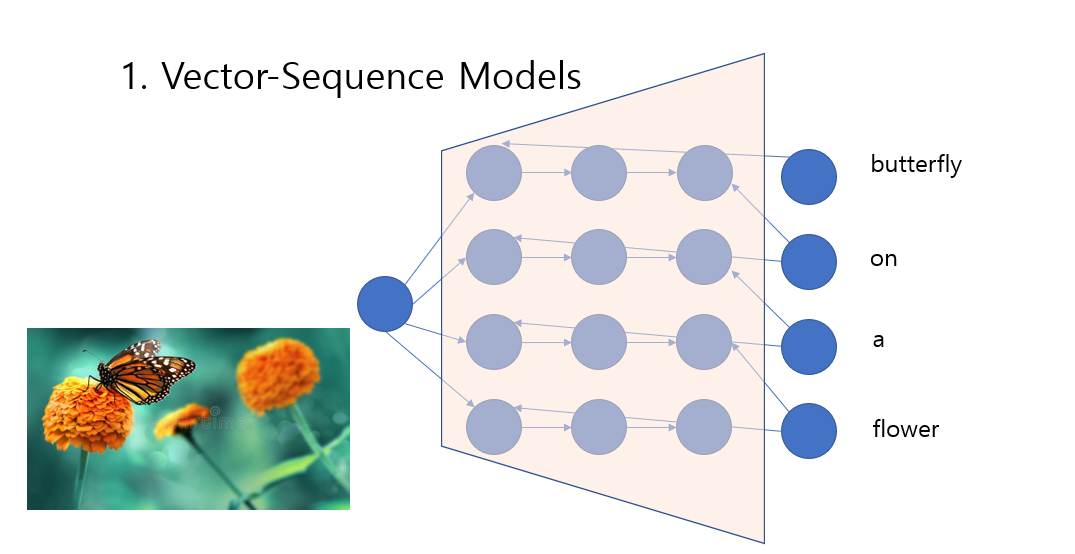
어떤 사진(벡터로 표현된)을 보고 어떤 사진인지 문장을 표현 할 수도 있고

문장을 통해서 사용자의 평가를 읽어내는 것 처럼 시퀀스를 벡터 하나로 표현하는 모델로 사용도 가능 할 것이다.
하지만 오늘은 attention에 집중할 것이기 때문에 일단 문장과 문장 즉, 시퀀스와 시퀀스에 집중해보자.

위 사진은 문장을 생성해 내는 모델이다. sos는 start of sequence 로 문장의 시작을 알리는 녀석이다. 해당 녀석이 네트워크에 들어가면 the 라는 녀석이 나온다. 그러면 우리는 두 번째 입력으로 the를 넣는다.
왜 출력을 다시 입력으로 넣어줄까?
왜냐하면 우리가 원하는 결과는 '문장' 이기 때문이다. 우리는 이전 값과 관련있는 녀석이 나오길 원한다. 아무렇게나 나오는게 아니라 이어진 문장을 원하는 것이다.
이걸 이미지의 관점에서 살펴보자.
이미지에서 생성모델이라 불리는 녀석들이 있다. 바로 이미지를 만들어 내는 모델들이다.
이전 포스팅을 봤다면 사람들의 손글씨로 이루어진 MNIST라는 데이터가 뭔지 알 것이다.
어떤 모델이 이런 손글씨 사진을 만들어 내게 하고싶다면 어떻게 해야 할까?
여기서 가장 기초적으로 사용되었던 autoregressive model로 접근해보자. (용어는 잘 몰라도 된다.)
이미지는 픽셀로 이루어져 있다. 각 픽셀은 256가지의 값을 지닌다. color 이미지의 경우 256 * 3의 값을 지닐 수 있다.
어떤 손글씨 이미지를 생성해야 한다면 그 모델은 차례대로 픽셀들을 생성하면서 이전에 생성했던 픽셀 값들을 기반으로 다음 픽셀을 어떤 것을 생성해야 하는지 결정한다고 생각할 수 있다.
그리고 이는 사실 RNN을 통해 어느정도 이해 할 수 있다.
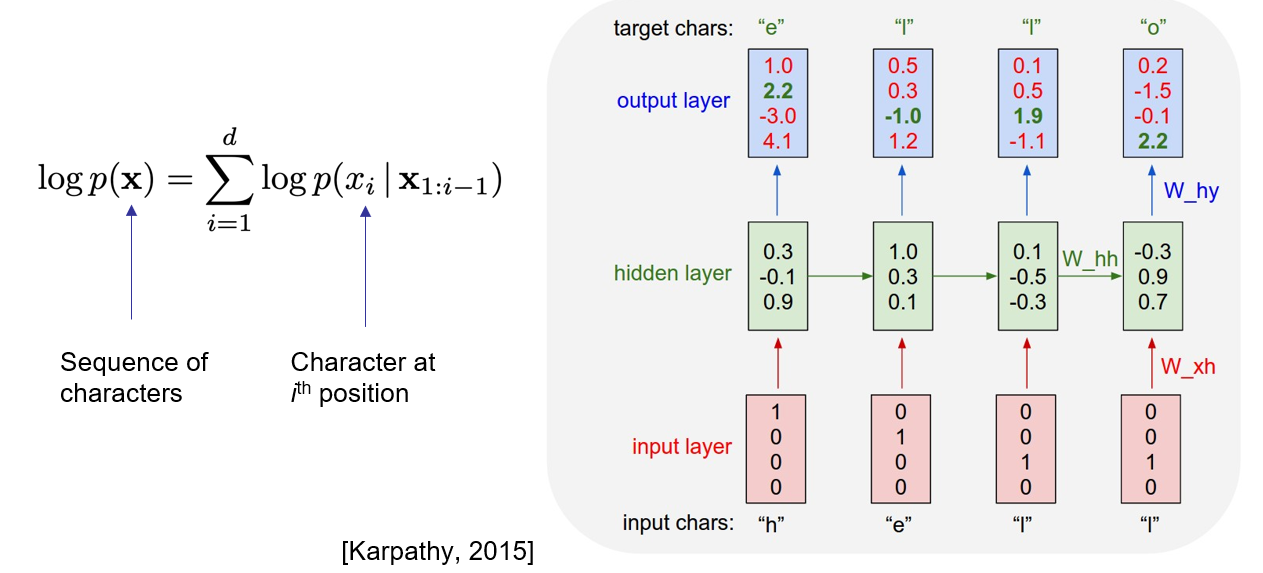
RNN은 이전 값들을 기반으로 다음 출력을 예측한다. 이를 이미지 생성에 활용하면 어떻게 될까?
각각의 픽셀들을 출력하고, 그걸 다시 다음 입력으로 넣고 해당 입력을 통해 다음 값을 출력하고... 이를 반복하는 것이다.
해보자.

epoch는 학습시킨 횟수라고 생각하면 편하다. 확실히 학습을 꽤 오래 시키다 보니 그럭저럭 뭔가 손글씨 같은 녀석이 나왔다. 하지만 조금 불안불안 하다.
왜냐하면 사실 이미지는 좌,우만 붙어있는 것이 아닌 위, 아래도 붙어있기 때문이다. 물론 네트워크를 오래 학습시키면 이러한 사실을 스스로 학습해 나가긴 하지만 이는 꽤나 어려운 일이다.
그렇다면 위치 정보를 같이 넘겨주면 어떻게 될까? (위치 정보는 hidden layer에 바로 넣어주었다. 자세한 내용이 궁금하면 나중에 포스팅 될 CV관련 게시물을 보자...)

위의 결과보다는 조금 더 잘 만든 모습이다.
그런데 생각해보면 RNN이라는 녀석은 이전 정보를 '암시적'으로 전달한다. 옆으로 계속 전달하긴 하지만 그 값이 있는 그대로 들어오는 것이 아닌 전달에 전달로 이어지는 것이다.

등에 그림 그리는 영상같은 것만 봐도 사람이 몇 명 지나가면 그림이 이상해 지는데 RNN이라고 별 수가 있는 것이 아니다. 길어지면 길어질수록 전달 할 내용은 점점 더 흐려진다.
이는 NLP에서도 마찮가지다. 어떤 문장을 생성한다고 생각해보자.(예를 들면 번역) 어떻게 생성할까?

간단하다. 특정 문장을 하나의 벡터로 모으는 것이다. 위 그림에서 F(h,...,h)로 표현된 저 녀석이 바로 RNN을 지나면서 모인 벡터인 것이다. 하나의 벡터를 통해서 전체 문장을 표현하고 이를 위에서 설명한 문장을 출력하는 방식으로 다른 언어로 바꾸는 것이다.
그런데 잘 될까?
잘 된다! 기존의 방식들에 비해서는!
하지만 썩 맘에 들지 않는다.
단순히 매 순간의 최고의 확률 값을 가져다 주는 단어를 출력하는 Greedy inference방식이나 이를 조금 더 개선시키고자 등장한 Beam Search와 같은 방법으로 RNN을 향상시킨다 한들 RNN은 태생적인 문제점을 지니고 있다. 바로 same encoder embedding에 의존한다는 것 (하나의 벡터에서 전체 문장을 만들려고 한다는 것), 그런데 이러한 하나의 벡터를 encoder 하면서 계속 전달하는 방식으로 저장한다는 것. (등에 대고 그림 그리는 것처럼 정보 손실이 일어날 수 있다.)
문제다 문제.
CV에서는 이러한 암시적인 정보전달을 직접적인 정보전달로 바꾸기 위해 다양한 시도를 했다.

그 중에 첫 번째 격이라 할 수 있는 녀석이 바로 MADE이다. 오른쪽 그림을 잘 보면 출력 1은 아무런 연결이 되어있지 않다. 즉 1번은 그냥 생긴다는 것이다. 그에 반해 출력 2번의 경우 화살표를 따라가보면 입력 1번 즉, x2와만 연결되어 있다. 이는 출력 2번을 만들 때 입력 1번만 보고 만든다는 것이다. 출력 3번은 입력 1, 2와 연결되어 있다. 이는 출력 3번을 만들 때 입력 1, 2를 통해 만든다는 것이다.
이런 식으로 각각의 픽셀들을 첫 번째 픽셀은 그냥 생성되도록, 두번째는 그 첫번째를 다시 입력으로 넣어서 해당 입력만을 통해 영향을 받아 생성하도록, 세번째 픽셀은 앞선 두개에 영향을 받고 네번째는 3개의 영향을... N번째 픽셀은 N-1개의 픽셀들의 영향을 받으며 생성하도록 만들 수 있을 것이다.

그리고 이게 그 결과다.
위의 RNN과 어느게 더 나은지 보면 RNN이 더 낫다고 여길수도 있다. 사실 이녀석은 너무 초창기라서 좀 별로다...
하지만 이녀석은 단순히 모양만 따라하는 것이 아니라 가장 가까운 녀석을 실제 데이터 셋에서 찾아보면 같은 숫자, 비슷한 모양을 띈다는 점이 특징이다.
그런데 조금만 생각해보면 이전에 말했던 CNN을 활용하여 비슷한 행동을 할 수 있다는 것을 떠올렸을지도 모른다.

빨간 픽셀을 생성하기 위해서 파란 영역만 보면 되는 것 아닌가.?! 그렇다면
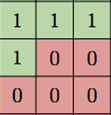
이런 커널을 사용하면 되지 않을까? 그렇게 등장한 것이 바로 PixelCNN이다.


뭐... PixelCNN은 옆을 못본다고 Gated PixelCNN이 등장하기도 했고 나중에는 PixelSNAIL과 같은 모델도 등장했다.
결과적으로는 저렇게 만들어진 모델은 다음과 같은 결과물을 냈다.

상당히 이전에 비해 깔끔한 결과물이다. 게다가 이녀석은 One-hot encoding of the labels를 input으로 넣어주면 conditional 하게 생성이 가능했다. 아주 초창기 모델이지만 우리는 이런 개념들을 attention과 연관지어서 생각해볼 수 있다.
CNN은 결국 주변 영역들에서 정보를 수집해오는 녀석이다. 그리고 attention도 주변 정보를 수집해오는 녀석이다.

한 레이어에서 다음 레이어로 넘어갈 때 Convolution과 Self-attention의 차이가 다음과 같다고 생각 할 수 있다. 즉, 다른 레이어들의 값을 참조하여 다음으로 전달할 값을 결정하는 것이다.
자 다시 NLP로 돌아가보자.

Attention은 저 s1이라는 녀석을 만들 때, 이전 값들을 모두 활용해서 만들어 보자는 것이다. 간단한 아이디어라 할 수 있다. 그리고 매우 강력하다.
이런 attention의 방식은 3가지 정도로 나눠볼 수 있다.
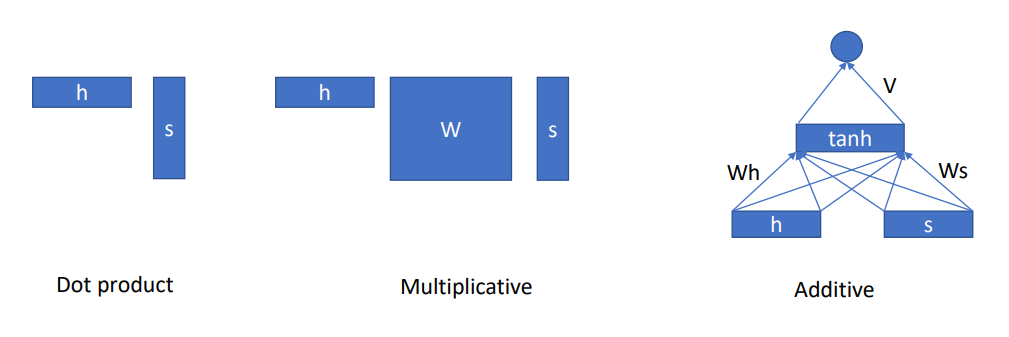
그리고 이 시리즈의 목적인 Transformer에서는 query, key, value를 활용한 닷프로덕트를 주로 사용한다.

이와 관련된 자세한 개념은 다음 게시물에서 다루도록 하겠다.
정리하자면 attention이란 생성할 때 다른 값들을 참조하여 생성하는 것이다. 이 때 전체를 다 볼수도 있고 (Global attention) 일부분만 볼 수도 있다. (local attention - CNN도 일종의 local attention이라 생각할 수도 있다.)
'NLP' 카테고리의 다른 글
| Transformer를 알아보자 [Attention is all you need] (0) | 2021.06.11 |
|---|---|
| NLP Task 정리 (0) | 2021.06.11 |
| NLP 벤치마크 GLUE (0) | 2021.06.11 |
| RNN과 LSTM (0) | 2021.05.02 |
| Word Embedding (0) | 2021.05.02 |